萬字詳解 從數據架構到指標定義——一篇文講透數據那些事兒與信息系統集成服務
在數字化轉型浪潮中,數據已成為驅動企業決策與創新的核心引擎。無論是構建穩健的數據架構、設計高效的數據存儲方案、規劃合理的數倉體系,還是定義清晰準確的業務指標,每一個環節都深刻影響著企業數據價值的釋放。與此信息系統集成服務作為連接業務與技術的橋梁,確保數據能夠順暢流動并賦能于業務場景。本文旨在系統性地闡述這一完整鏈條,為您打通數據從產生到應用的全過程。
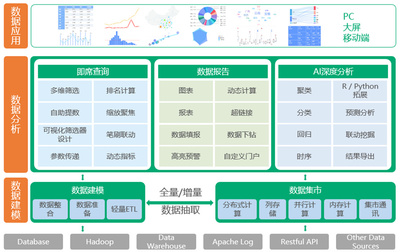
一、 數據架構:構建數據體系的頂層藍圖
數據架構是企業級數據戰略的頂層設計,它定義了數據如何被組織、管理、集成與使用。一個優秀的數據架構應具備清晰性、靈活性、可擴展性和安全性。
- 核心目標與原則:數據架構旨在實現數據資產化、服務化和價值化。其設計遵循業務驅動、統一標準、數據共享、安全合規等基本原則,確保數據能夠支撐多變的業務需求。
- 核心組件:
- 數據模型:包括概念模型(描述業務實體與關系)、邏輯模型(獨立于技術的詳細結構)和物理模型(針對具體數據庫的實現)。
- 數據流:明確數據從源頭(如業務系統、IoT設備)到消費端(如報表、應用)的流動路徑、轉換規則與依賴關系。
- 數據治理框架:涵蓋數據標準、元數據管理、數據質量、數據安全與隱私保護等,是保障數據可信、可用的基石。
- 技術選型:根據數據規模、處理時效(批處理/實時)、成本等因素,選擇適合的數據庫、大數據平臺、計算引擎等技術棧。
二、 數據存儲:數據的物理承載與組織策略
數據存儲關注數據在物理介質上的存放方式、結構與訪問效率。
- 存儲層級:通常分為在線交易處理(OLTP) 數據庫(支持高并發、小事務的增刪改查,如訂單系統)、在線分析處理(OLAP) 存儲(針對復雜查詢與分析優化,如數倉)、數據湖(以原始格式存儲海量原始數據,支持靈活分析)和歸檔/冷存儲(存儲低頻訪問的歷史數據)。
- 存儲模型:
- 結構化存儲:關系型數據庫(RDBMS),使用行和表,強Schema,適合事務處理。
- 半結構化/非結構化存儲:NoSQL數據庫(如文檔型MongoDB、鍵值型Redis、寬列族Cassandra、圖數據庫Neo4j)、對象存儲(如AWS S3),適合靈活多變、非關系型或海量文件數據。
- 關鍵考量:性能(IOPS、吞吐量、延遲)、成本、可擴展性(水平/垂直)、持久性、備份與恢復機制。混合存儲策略(如“湖倉一體”)成為趨勢。
三、 數倉設計:面向分析的數據組織藝術
數據倉庫是一個面向主題的、集成的、相對穩定的、反映歷史變化的數據集合,用于支持管理決策。
- 經典分層架構:
- 操作數據層(ODS):接近源系統的原始數據鏡像,用于數據緩沖與輕度清洗。
- 數據倉庫層(DW):核心層,進行深度集成、清洗、轉換,形成企業一致的事實與維度模型。常用維度建模技術,如星型模型、雪花模型,圍繞“事實表”(度量指標)和“維度表”(分析角度)構建。
- 數據集市層(DM):面向特定部門或業務線(如銷售、財務)的定制化數據子集,查詢性能更優。
- 應用數據層(ADS) 或 數據服務層:為報表、BI工具、API接口提供高度聚合、可直接使用的數據。
- ETL/ELT流程:數據從源系統到數倉的移動與加工過程。Extract(抽取)、Transform(轉換)、Load(加載)是核心步驟。現代云數倉更傾向于ELT(先加載原始數據到強大算力平臺,再轉換)。
- 現代演進:隨著云原生與實時分析需求,實時數倉(基于Flink、Kafka等流處理技術)和湖倉一體(融合數據湖的靈活性與數倉的管理性)成為重要方向。
四、 指標定義:衡量業務成效的統一語言
指標是將業務目標量化的標尺,是數據價值呈現的最終出口。混亂的指標定義是導致“數據孤島”和決策分歧的常見原因。
- 指標體系設計:
- 北極星指標:唯一的核心指標,體現產品/業務的核心價值。
- 分層分級:從上至下拆解,如一級指標(公司戰略層)、二級指標(業務線/部門層)、三級指標(執行監控層)。
- OSM模型:結合目標(Objective)、策略(Strategy)、度量(Measurement),確保指標與行動對齊。
- AARRR模型(海盜模型):適用于用戶增長領域,從獲客、激活、留存、收入到推薦的全流程指標。
- 定義要素:一個規范的指標定義必須清晰包含:指標名稱、業務含義、計算公式(分子、分母、可能的分段或過濾器)、統計維度(可按時間、地區、渠道等分析)、數據來源(來自哪張表、哪個字段)、更新頻率和負責人。
- 管理與治理:建立企業級指標字典或指標平臺,統一管理口徑,實現“一處定義,處處使用”,避免歧義。
五、 信息系統集成服務:打通數據與業務的“最后一公里”
前述所有數據能力的最終價值,需要通過信息系統集成服務落地到具體的業務場景和用戶流程中。
- 核心價值:集成服務旨在打破系統間壁壘,實現數據、流程、應用的互聯互通,提升運營效率與協同能力。
- 集成模式:
- 數據集成:通過ETL/ELT、CDC(變更數據捕獲)、數據同步工具等,實現跨系統數據匯聚與共享,是構建數倉的基礎。
- 應用集成:通過API(RESTful、SOAP)、消息中間件(如Kafka、RabbitMQ)、企業服務總線(ESB)或iPaaS(集成平臺即服務),實現應用間功能調用與流程自動化。
- 流程集成:將分散在不同系統中的業務流程片段串聯成端到端的自動化流程,常借助BPM(業務流程管理)工具。
- 用戶界面集成:通過門戶、統一工作臺等方式,將多個應用界面整合,提供一致的用戶體驗。
- 實施關鍵:
- 統一規劃:基于企業架構(EA)進行頂層設計,避免點對點集成的混亂。
- 標準先行:制定統一的接口規范、數據格式標準(如JSON Schema)、安全協議(如OAuth)。
- 松耦合設計:采用微服務、事件驅動架構(EDA)等,提高系統靈活性與可維護性。
- 全生命周期管理:涵蓋接口的設計、開發、測試、部署、監控、版本管理與退役。
從融合到賦能
數據架構、存儲、數倉設計與指標定義,構成了從數據底層治理到頂層應用的完整閉環。而信息系統集成服務則是確保這一閉環能夠緊密嵌入業務價值鏈的粘合劑。在實踐過程中,這五個方面并非線性順序,而是需要迭代循環、相互反饋。
隨著人工智能與機器學習的深度融入,數據架構將更趨智能化(如智能分層、自動優化),數倉將向“智能數據倉庫”演進,指標定義將更加動態與預測性,而集成服務也將更加自動化與自適應。理解并掌握這“數據那些事兒”,是企業構建數據驅動型組織、實現數字化轉型不可或缺的核心能力。
如若轉載,請注明出處:http://m.fejyfw.cn/product/69.html
更新時間:2026-04-07 01:07:07